
La cellule est l'unité structurale et fonctionnelle de tous les êtres vivants. Les organismes les plus simples sont formés d'une seule cellule (ex. : bactérie), alors que les organismes plus complexes peuvent être composés de milliers, de millions ou même de milliards de cellules (ex. : plantes, mammifères).
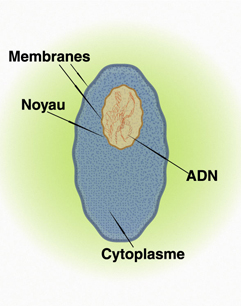
Les cellules ont toutes un rôle particulier à jouer selon qu'elles forment les organes, les muscles, la peau, etc. Chaque cellule possède un noyau dans lequel on trouve, entre autres, l'acide désoxyribonucléique (ADN), le même ADN que l'on retrouve dans toutes les cellules du même organisme. L'ADN y est regroupé en chromosomes. L'être humain porte 23 paires de chromosomes dans le noyau de chacune de ses cellules. Lorsqu'elle se reproduit, la cellule se divise. L'ADN de la cellule mère est alors reproduit d'une façon identique pour former l'ADN de la cellule fille.
L'ADN est la molécule de l'hérédité qui forme les chromosomes et qui contient l'ensemble des gènes. Chaque gène est un bout d'ADN qui contient, sous forme codée, toute l'information relative à la vie d'un organisme vivant, du plus simple au plus complexe, qu'il soit animal, végétal, bactérien ou viral1 2. Ce concept est nommé l'universalité du code génétique. Cette information sert à fabriquer les protéines dont un organisme a besoin. Les protéines ainsi formées ont différentes fonctions qui consistent essentiellement à assurer la croissance et l'autonomie d'un organisme et sa reproduction.
L'ADN contient donc tous les éléments d'information susceptibles de faire vivre et de concevoir un organisme.
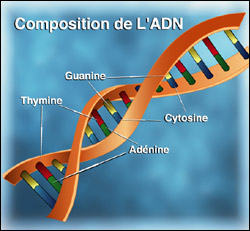 La molécule d'ADN se présente sous la forme schématique d'une double hélice enroulée.
La molécule d'ADN se présente sous la forme schématique d'une double hélice enroulée.
Cette double hélice est une grosse molécule qui regroupe des molécules plus petites appelées nucléotides. Chaque nucléotide est constitué par l'union de trois autres petites molécules.
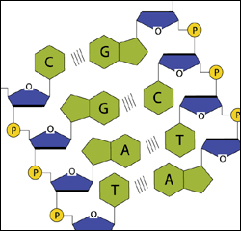
C'est d'ailleurs le sucre (le désoxyribose) qui donne son nom à l'ADN.
Ce qui différencie un nucléotide d'un autre est la nature de la base azotée (« lettre » de l'alphabet de l'ADN). Le sucre et le phosphate restent les mêmes. Les bases azotées sont au nombre de quatre, soit :
Le squelette de la double hélice est constitué d'associations deux à deux des bases azotées selon l'ordre imposé pour un codon donné. L'adénine (A) se lie toujours avec la thymine (T), la cytosine (C) toujours avec la guanine (G). Ces molécules seront face à face et se stabiliseront par des interactions appelées liaisons hydrogènes.
Il existe une interaction à deux liaisons hydrogènes entre l'adénine et la thymine :
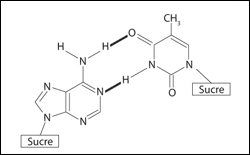
Il existe une interaction à trois liaisons hydrogènes entre la guanine et la cytosine :
Ainsi, les liaisons hydrogènes assurent la stabilité de la molécule d'ADN qui prend une forme de double hélice.
La synthèse des protéines correspond à la conversion du message contenu dans l'ADN (les gènes). L'ADN présent dans le noyau contrôle la synthèse des protéines, qui s'effectue dans le cytoplasme de la cellule. Cependant, l'ADN ne quitte pas le noyau au cours de ce processus. Un messager (une molécule d'ARN particulière) participe à la transmission du message vers le cytoplasme. Chaque molécule d'ARN messager sort éventuellement du noyau et pénètre dans le cytoplasme, transportant son message pour la synthèse d'une protéine spécifique.
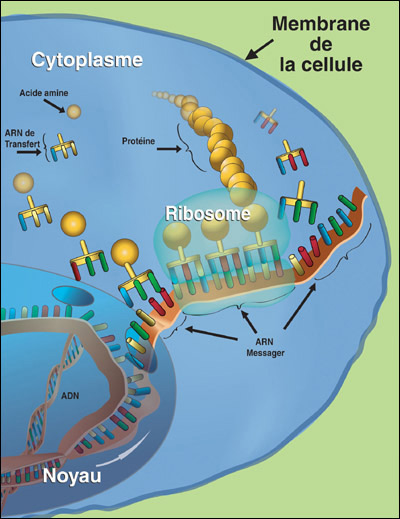
On trouve dans le cytoplasme une petite « structure » appelée ribosome et deux types d'ARN (ARN messager et ARN de transfert) qui participent à l'assemblage des acides aminés alors libres dans le cytoplasme.
La cellule est l'unité structurale de tous les êtres vivants et l'ADN est l'un des constituants du noyau de cette cellule. Chez tous les organismes l'alphabet de l'ADN est constitué de 4 « lettres », au lieu de 26 comme dans notre alphabet, soit A, C, G et T. Pour traduire l'ADN en protéines, ces lettres s'alignent en grande chaîne dans un ordre différent, en groupe de trois (ex. : ACG, CGA, etc.). Ces séquences correspondent à des « mots » selon le type de protéines à coder. Les chaînes de « lettres » s'associent ensuite deux par deux en forme de double hélice (échelle spiralée). Les barreaux de « l'échelle » sont les liens entre les A et les T ou les liens entre les C et les G. Lorsque les deux brins sont associés, la molécule d'ADN prend une forme en trois dimensions (3D). Dans cette échelle, nous trouvons des sections (« phrases ») appelées gènes. Chaque gène constitue la recette pour construire une protéine spécifique avec l'aide de l'ARN.
Les protéines sont formées de chaînes d'unités plus petites appelées acides aminés, qui s'unissent entre eux par des liens dits peptidiques.
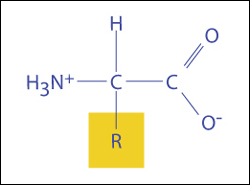 Structure de base d'un acide aminé
Structure de base d'un acide aminé
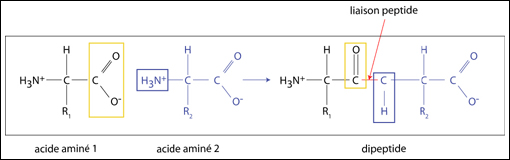 Détails de la formation d'un lien peptidique entre deux acides aminés
Détails de la formation d'un lien peptidique entre deux acides aminés
Dans la nature, toutes les cellules vivantes des différents organismes (plantes, animaux, humains, etc.) élaborent leurs protéines à partir de 20 types d'acides aminés. Le nombre d'acides aminés dans les protéines est très variable (de 50 à 3000). Les protéines diffèrent non seulement par le type et par le nombre d'acides aminés qu'elles contiennent, mais aussi par la disposition de ceux-ci.
Les protéines ne restent pas sous la forme de chaîne linéaire : elles se replient sur elles-mêmes en une structure particulière en trois dimensions (3D). La forme d'une protéine est cruciale pour qu'elle puisse exercer sa fonction. Les protéines se retrouvent dans chaque structure essentielle des cellules vivantes où elles jouent différents rôles. Parmi les protéines, on trouve, entre autres, les anticorps, les hormones et les enzymes qui contrôlent les réactions chimiques qui constituent les activités vitales des cellules.
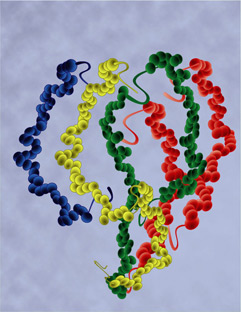 Structure tridimensionnelle d'une protéine
Structure tridimensionnelle d'une protéine
Le contenu en protéines des différentes espèces varie beaucoup. Les spécimens d'une même espèce ont en commun plusieurs types de protéines.
Lorsque nous consommons des protéines animales ou végétales, nous absorbons des protéines étrangères à notre organisme et celles-ci ne peuvent pas directement servir à l'élaboration de nos propres tissus. Cependant, durant la digestion, elles sont à nouveau dissociées en acides aminés.
Par la suite, lors de la synthèse des protéines dans les cellules, les acides aminés sont à nouveau combinés pour former de nouvelles protéines.
De par leur structure, les lipides sont une excellente réserve d'énergie pour les cellules.
Les lipides constituent également une classe importante de composés retrouvés dans les cellules vivantes. Ces composés ne sont pas solubles dans l'eau. Les lipides les plus abondants sont les graisses, les huiles et les cires.
Tous les lipides contiennent, dans leur structure, un ou plusieurs acides gras.
Il est possible, par transgénèse, de modifier les lipides d'un organisme. Le principal objectif de cette modification étant de donner une nouvelle composition ou de nouvelles propriétés à l'huile extraite de l'OGM (ex. soja GM avec moins d'acide gras saturé.
La formule générale d'un acide gras s'écrit de la façon suivante : R-COOH
Dans cette formule, le radical R correspond à une chaîne carbonée (chaîne de carbone) constituée uniquement d'atomes de carbone (C) et d'hydrogène (H). Les acides gras trouvés dans la nature ont toujours un nombre pair d'atomes de carbone dans leur molécule.
Un acide gras est dit saturé quand ses atomes de carbone sont reliés les uns aux autres par un seul lien et que tous les liens libres portent chacun un atome d'hydrogène.
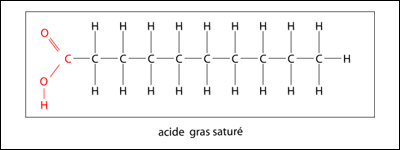
Un acide gras est dit insaturé quand il y a présence d'une double liaison (mono-insaturé) ou de plusieurs doubles liaisons (polyinsaturés) entre ses atomes de carbone.
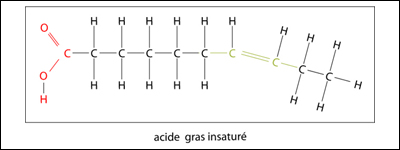
Du point de vue structural, les acides gras, qu'ils soient saturés ou insaturés, représentent les petites molécules qui servent à la formation des moyennes et des grosses molécules de lipides. Du point de vue fonctionnel, les acides gras constituent un carburant énergétique utilisable par la majorité des cellules, à l'exception des cellules nerveuses.
Des sucres peuvent être ajoutés sur les protéines lors de leur synthèse. Ce processus s'appelle glycosylation. Les sucres ajoutés peuvent être différents selon l'organisme. La présence de ces sucres peut poser problème lors de la transgénèse (synthèse d'une protéine d'un organisme dans un autre). Par exemple, si une protéine d'un animal nécessite un sucre particulier pour être active et qu'elle est produite avec un autre type de sucre chez une plante, il se peut que la protéine ne soit pas active ou provoque des réactions non désirées.
Les glucides simples ou hydrates de carbone sont solubles dans l'eau. Ils sont importants du fait que, pour la plupart, ils constituent une source d'énergie pour les cellules des organismes, aussi bien pour les végétaux qui les synthétisent que pour les animaux. Ils se divisent en trois classes : les monosaccharides, les disaccharides et les polysaccharides.
Les sucres simples ou monosaccharides sont les glucides les plus abondants. Le glucose est l'un des plus importants et on le trouve en abondance dans les plantes et les animaux.
Le glucose, un glucide, est la principale source d'énergie des cellules vivantes.
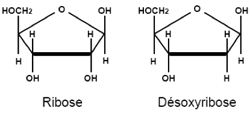 Ex. : monosaccharides présents dans l'ARN (ribose) et l'ADN (désoxyribose)
Ex. : monosaccharides présents dans l'ARN (ribose) et l'ADN (désoxyribose)
Un disaccharide est composé de deux molécules de monosaccharides liées ensemble. Une molécule de glucose peut se lier à une molécule de fructose pour former le sucrose ou sucre de canne (sucre de table ordinaire). Une molécule de glucose qui se joint à une molécule de galactose produit du lactose ou le sucre du lait.
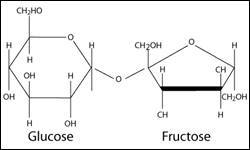 Ex. : disaccharide – le sucrose
Ex. : disaccharide – le sucrose
Les polysaccharides sont des glucides complexes formés de chaînes de monosaccharides (sucres simples). Le glycogène est un long polysaccharide de glucose produit dans le foie et dans les muscles et sert de réserve de glucides pour les cellules animales. Les amidons de maïs et de pommes de terre sont également des polysaccharides. La cellulose est un polysaccharide très complexe formé dans les cellules végétales.

